はじめまして、フロントエンドエンジニアの菅野です。
今回は、E2Eテスト自動化の取り組みについてお話ししたいと思います。
E2Eテストとは
End to Endを略してE2Eと呼ばれています。
例えば、
- CV(コンバージョン)ポイントやログイン機能の動作確認
- VRT(ビジュアルレグレッションテスト)
など、システム全体が正しく動作するかを確認するものです。
なぜE2Eテストを導入するのかというと、以下のような目的とメリットが挙げられます。
リリース時の確認コストの削減と品質担保
LPや2P~3Pといった小規模なサイトだと確認コストはそんなにかかりませんが、中〜大規模になると人の手で一つ一つ確認していくと時間と手間がかかりとても大変です。
そこで人が手を動かさずに各ページのUIや挙動をチェックすることができればコスト削減が見込まれます。
また、例えばリリース後に表示崩れが起きていたとします。
これまでだとリリースしてから5日後に気づいていたのが、リリース時にテストを実行することで1〜2時間といった短時間で発見でき、品質担保としても有効な手段となります。
ツールの選定
E2Eテストツールはいくつかあり、
- Selenium
- Puppeteer
- Cypress
はよく耳にするのではないでしょうか。
他にはマイクロソフト製のPlaywrightというライブラリが2020年5月にリリースされています。
そんな様々なツールがある中で今回選んだのが「TestCafe」です。
TestCafeとは
アメリカのDeveloper Express Inc.という企業が開発しているE2Eテストツールで、ブラウザテストを自動化するためのフレームワークです。
2016年にリリースされており、比較的新しいツールといえます。
特徴
- async/awaitの仕様を前提にAPI設計がされている
- TypeScriptサポート
- 通常のJSだけでなくTypeScriptで記述したテストコードをそのまま実行できる
- 構築が簡単
- SeleniumではWebDriverのクライアントとテストを実行する各ブラウザのWebDriverのインストールが必要だが、TestCafeはnpmでTestCafeをインストールするだけでOK。設定ファイルも必要なくテスト環境が整う。
- 非WebDriver依存
- 一昔前のE2Eテストツールは、各種ブラウザベンダ間の差異を吸収し、抽象化して操作するためにWebDriverを使うのが常識でしたが、現在はブラウザ側がサポートするようになり、テストツール側が意識しなくてよくなった。TestCafeもこれを前提に設計されている。
- BDD(ビヘイベア駆動開発)に則ったテストコード
- UIテスト手順をメソッドチェーン形式で記述。これにより、ユーザー操作や外部仕様をまるで自然言語のようにコードで表現できる。つまり、テストコードがそのままテスト仕様書となる。
- サポートブラウザが豊富
- TestCafeだけでなく、Node.jsすらインストールされていない環境であっても、テストを実行することが可能
- その場合、TestCafeが出力するURLを対象の環境のブラウザで開くだけでテストが開始される。ただし、TestCafeがインストールされているホストと対象とするデバイスが同一ネットワーク上に存在する必要がある。
- BrowserStackとの連携をサポート
- E2Eテストの実行環境は開発マシンとは別に用意しておくことが望ましい。そうすることで開発(実装)と並行してテストを実行しやすくなる。
以上の特徴があり、
- サポートブラウザが豊富
- 構築が簡単
- async/awaitとを含む最新のJS機能とTSをサポート
が大きな選定理由となります(あとTestCafeっていう名前が可愛かった)
テスト項目
- VRTテスト
- CVポイント(フォーム)の基本動作確認
- metaやOGPの取得
- マークアップチェック
この4項目のテストを行います。
VRTテスト
VRTとは、画像回帰テストと呼ばれており、画面のスクリーンショットをリリース前後で比較することで表示崩れを確認することができるテストです。
TestCafeとreg-cli*1を組み合わせて実装していきます。
reg-cliで生成されたHTMLを見てみると

このように差分を確認できるようになります。
おまけ
スクリーンショットが複数枚ある場合は、それぞれを連結させて1枚の画像にすると1枚1枚開いて確認する手間が省けるのでおすすめです。
sharpという画像編集ライブラリを使うと実装できます。
CVポイント(フォーム)の基本動作確認
フォームが入力〜送信まで問題なく動作するかをチェックします。
バリデーションや様々なパターンを想定してテストが実行できると良いですが、テストケースがかなりのボリュームになり、コストがかかり過ぎてしまう可能性もあるので、どこに重点を置くかを決めてテストケースを絞るのが現実的かなあと思います。
fixture('FormTest Start'); .page('https://example.com'); test('必須項目を入力し送信', async (t: TestController) => { const dataTarget = await Selector('[data-target-input]'); const name = dataTarget.withAttribute('name', 'name'); const mail = dataTarget.withAttribute('name', 'email'); const phone = dataTarget.withAttribute('name', 'phone'); const submitBtn = await Selector("button"); await t .typeText(name, 'テスト名前') .typeText(mail, 'test_sample@gmail.com') .typeText(phone, '0312345678') .click(submitBtn.withExactText('送信')) });
このように直感的に書けるので分かりやすいのではないでしょうか。
metaやOGPの取得
ページを一つ一つ開き、デベロッパーツールや拡張機能を使ってmeta情報を確認するのはとても面倒です。
スクリーンショットを撮るタイミングで各ページのmeta情報を取得し、jsonに吐き出すことで確認コストを削減します。
og:imageは外部のOGP確認ツールにアクセスし、スクリーンショットを撮影します。
テキスト情報だけでなくog:imageを視覚的に確認できるようにしています。
{ "meta": [ { "page": "/", "title": [ { "text": "株式会社Sample", "最大29文字程度": true } ], "description": [ { "text": "株式会社Sampleのdescriptionが入ります。", "最大110字程度": true } ], "keyword": [ { "text": "株式会社Sample,サンプル,sample,北海道,東京,大阪,福岡", "5〜6個程度": false } ], "og:title": "株式会社Sample", "og:url": "https://example.com/", "og:image": "https://example.com/img/ogp.png?1603865417442", "og:site_name": "株式会社Sample", "og:description": "株式会社Sampleのog:descriptionが入ります。", "canonical": "", "robots": null } ] }

マークアップチェック
テスト実行時にチェック用のCSSを挿入し、スタイルが当たった状態のスクリーンショットを撮影してマークアップチェックを行います。 ディレクターやデザイナーはソースコードをあまり見慣れていないため、視覚的に確認できるようにすることで、マークアップについてもチーム全体で意識を持ち、品質担保を目指すことができます。
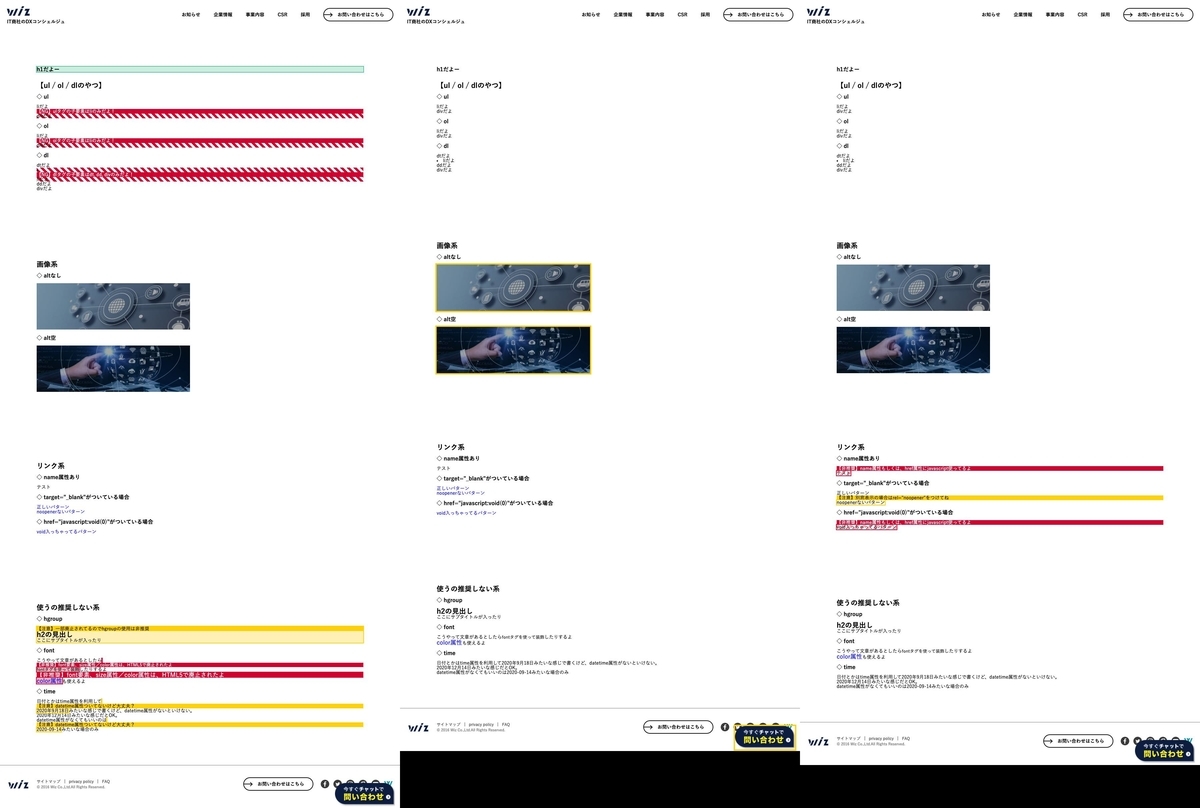
- ul,olの子要素にli以外のタグが入っている
- dlの子要素にdt,dd,div以外のタグが入っている
- imgタグのaltがないもしくは空
- リンクにname属性もしくはhref属性にjavascriptが使われている
- target="_blank"がついている場合にrel="noopener"
といった項目がチェックできるようになっています。
以上、4つの項目のテストを実行し、チェックを行っています。
実案件での使い方
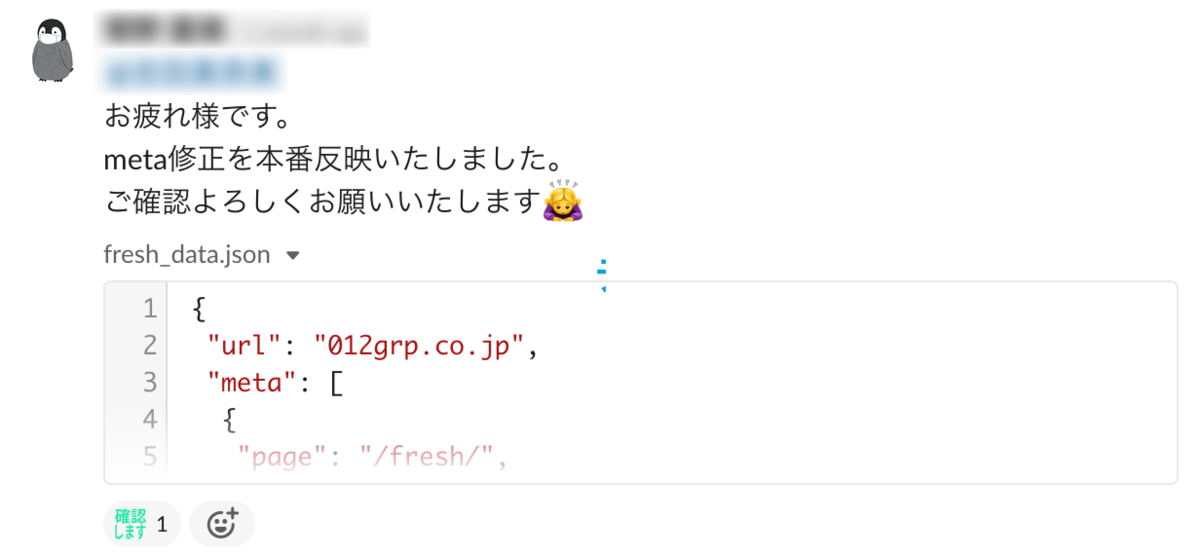
コーポレートサイトと新卒採用サイトでは新規コンテンツ制作時や複数ページに及ぶ修正が発生した際に必要なテストを実行し、結果をSlackでプロジェクトチームに共有して確認を行っています。 最近だとmetaを変更したのでjsonを共有して確認に使用してもらいました。
今後やりたいこと
Qiitaに詳しい実装方法は書いており、それを参考にWiz cloudにも導入してもらっていますが、他の案件にもスムーズに取り入れてもらえるようドキュメントを鋭意制作中です。
これで完成ではなく、アップデートして継続できるE2Eテストにしていけたらと思います!
最後に
Wizではエンジニアを募集中です!
興味のある方、ぜひご覧下さい。