こんにちは、インフラエンジニアの赤倉です。
こんにちは、インフラエンジニアの赤倉です。
昨年末にCentOS8のサポートが終了したばかりですが、CentOS7のサポート期限が2024年6月末に近づいてきています。
そこで今回は、CentOSの次にくるディストリビューション候補の中からAlmaLinux8への移行を試してみたいとおもいます。
移行環境
移行元CentOSの環境は弊社でよく使っているLaravel構成としました。
- CentOS Linux release 7.9.2009 (Core)
- Apache/2.4.6
- PHP 7.4.28
- Laravel Framework 8.83.1
- MySQL Ver 14.14 Distrib 5.7.37
Laravelは初期インストール+認証設定まで完了した環境を用意しました。
移行ツール
今回の移行ではAlamaLinuxから提供されている「Elevate」を使います。
手順は公式のクイックスタートガイドを参考にしています。
Elevateは他にも下記ディストリビューションへの移行をサポートしています。
移行の流れ
最新のCentOSアップデートをインストールして、再起動します。
$ yum update -y $ rebootelevate-releaseプロジェクトリポジトリとGPGキーを使用してパッケージをインストールします。
$ yum install -y http://repo.almalinux.org/elevate/elevate-release-latest-el7.noarch.rpmアップグレードするOSのleappパッケージと移行データをインストールします。
$ yum install -y leapp-upgrade leapp-data-almalinux下記のオプションに変更することにより、移行先のディストリビューションを選択できます。
- leapp-data-almalinux
- leapp-data-centos
- leapp-data-oraclelinux
- leapp-data-rocky
アップグレード前のチェックを開始します。
$ leapp preupgradeここで移行要件を満たしていない場合は下記のエラーメッセージが出力されます。
============================================================ UPGRADE INHIBITED ============================================================ Upgrade has been inhibited due to the following problems: 1. Inhibitor: Possible problems with remote login using root account 2. Inhibitor: Detected loaded kernel drivers which have been removed in RHEL 8. Upgrade cannot proceed. 3. Inhibitor: Missing required answers in the answer file Consult the pre-upgrade report for details and possible remediation.レポートファイル(/var/log/leapp/leapp-report.txt)を確認して修正対応します。
弊社環境の場合、下記の通り対応しています。
1. Inhibitor: Possible problems with remote login using root account
sshのrootログインを許可する。
$ echo PermitRootLogin yes | sudo tee -a /etc/ssh/sshd_config2. Inhibitor: Detected loaded kernel drivers which have been removed in RHEL 8. Upgrade cannot proceed.
CentOS8で廃止されたカーネルモジュールを読み込まないようにする。
$ rmmod pata_acpi $ rmmod floppy3. Inhibitor: Missing required answers in the answer file Consult the pre-upgrade report for details and possible remediation.
公式ガイドに記載のあったコマンドを実行する。
$ leapp answer --section remove_pam_pkcs11_module_check.confirm=Trueもう一度アップグレードのチェックコマンドを実行してエラーがないことを確認します。
$ leapp preupgradeアップグレードを開始します。
$ leapp upgrade途中、パッケージ重複エラーでプロセスが終了することがあります。
Error: Transaction test error: file /usr/lib64/.libcrypto.so.1.1.1k.hmac from install of openssl-libs-1:1.1.1k-5.el8_5.x86_64 conflicts with file from package openssl11-libs-1:1.1.1k-2.el7.x86_64その場合は、対象のパッケージを削除して再度アップグレードを開始します。
$ yum remove openssl-libs-*弊社環境では約5分でアップグレードが完了しました。また、その間もWebサービスは継続していました。
アップグレード完了後、サーバを再起動します。
$ reboot弊社環境では約15分で再起動が完了しました。
AlmaLinuxにアップグレードされていることを確認します。
$cat /etc/redhat-release AlmaLinux release 8.5 (Arctic Sphynx)
移行後の問題
なぜか
php-xmlのみ消えていたので、再度インストールしました。$ dnf install https://rpms.remirepo.net/enterprise/remi-release-8.rpm $ dnf module install php:remi-7.4 $ dnf module enable php:remi-7.4 $ dnf install php74-php-xml
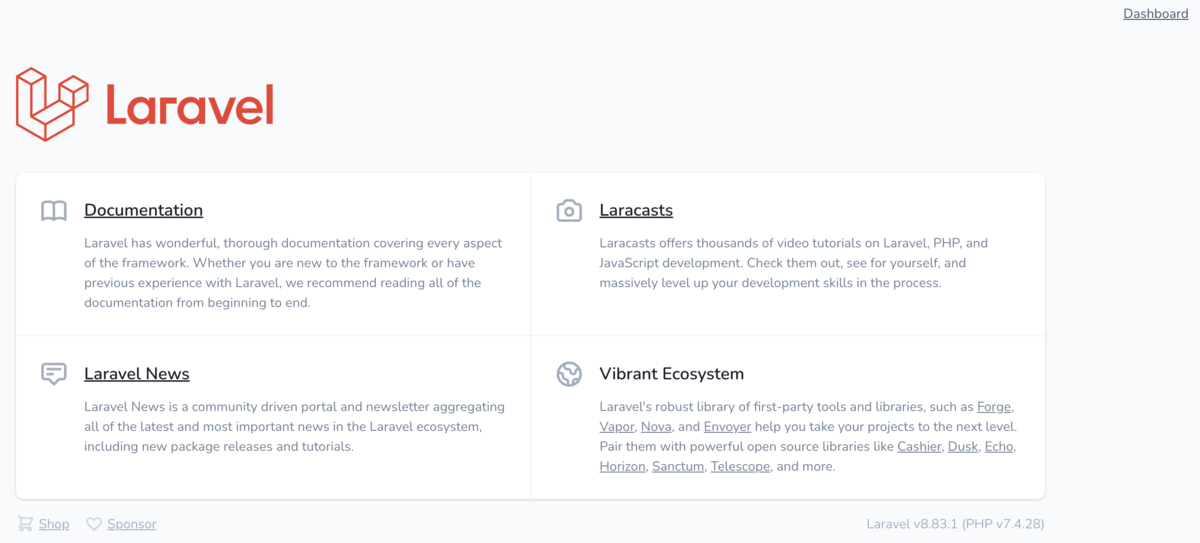
Webサイト(Laravel)確認
上記の問題を対応すれば、移行後の環境でもLaravelは正常に稼働していました。
最後に
「Elevate」 アップグレード前の問題を修正するのに時間がかかりましたが、思っていたより簡単に移行することができました。サーバの再起動に時間がかかるので実施の際はWebサービスの停止を予定しておく必要はありそうです。
インフラエンジニアの皆様も、CentOS7移行の際にはElevateお試しください!
株式会社Wizではエンジニアを募集しています!
↓↓↓興味ある方はぜひご覧ください!↓↓↓